利用 Azure OpenAI 搭建私有 AI 对话平台
搭建 Azure OpenAI
部署 Azure OpenAI 服务实例
Azure 是一个全球性的云计算平台,可类比国内的阿里云、腾讯云等,其控制台称为 门户 (Portal)。Azure OpenAI 允许用户在 Azure 上调用 OpenAI 模型,并且能够在中国境内使用。
要使用 Azure,你首先需要有一个微软企业账号(如 your-name@company-name.onmicrosoft.com),因为根据微软的政策,个人用户(如 your-name@outlook.com)无法直接使用 Azure OpenAI 服务。
对于企业用户,你可以在上方的搜索栏中搜索 Azure OpenAI,并部署相应的服务实例,如下图所示:
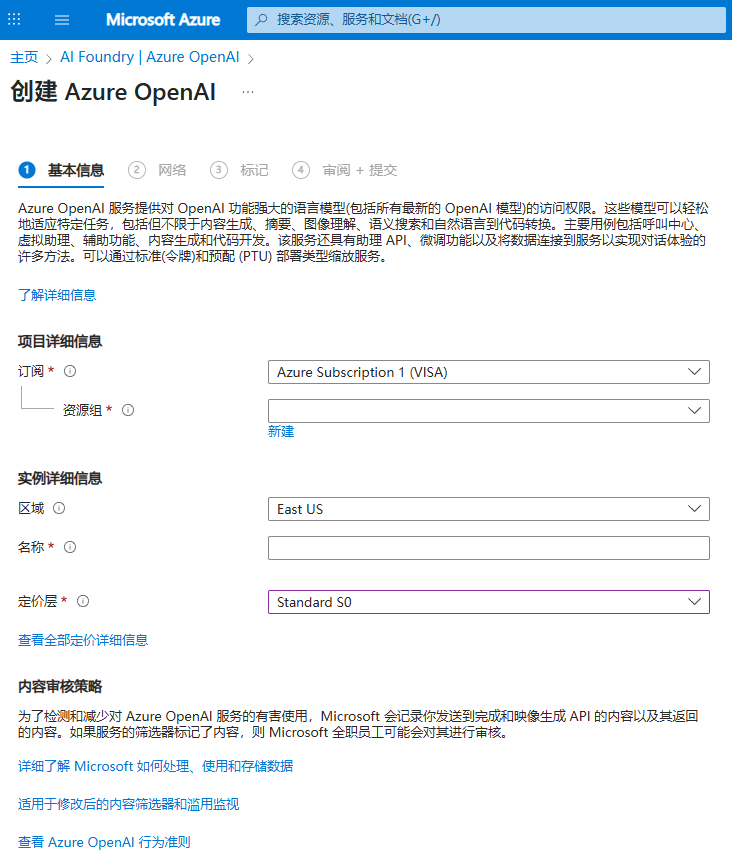
- 资源组 是 Azure 中用于管理和组织资源的容器。你可以将相关的资源(如虚拟机、数据库等)放在同一个资源组中,以便于管理和访问。
- 区域 是指 Azure 数据中心的物理位置。推荐选择 East US 2,支持更多 AI 模型。
- 名称 是你为资源组指定的唯一标识符,也是后续 Azure OpenAI 服务实例的根节点。
- 定价层 决定了你使用 Azure OpenAI 服务的费用。只能选择 Standard S0。
后续所有选项保持默认,一直选择 “下一页”,最后点击 “创建” 按钮完成部署。
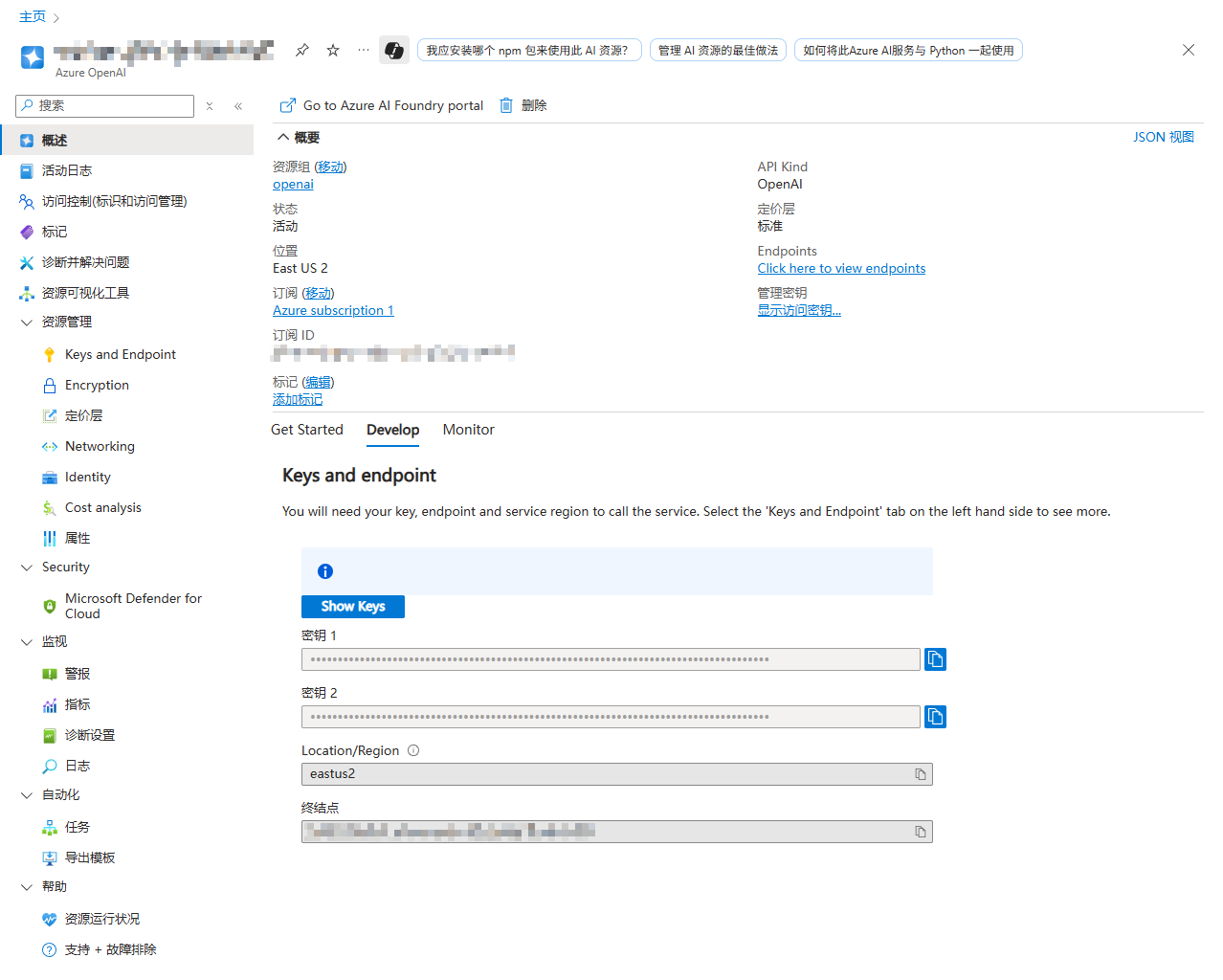
获取终结点和密钥
部署完成后,你就能在 Azure 门户首页找到刚刚创建的 Azure OpenAI 服务实例。点击进入该实例,你将看到 “概述” 页面,下面的 “Develop” 选项卡包含了 “终结点” 和 “密钥” 信息。请妥善保存这些信息,以便后续使用,同时注意保密。
在 Azure OpenAI 上部署模型
点击 “Get Started” 选项卡中的 “Explore Azure AI Foundry portal”,进入 Azure AI Foundry 门户。在左边的菜单中选择 “模型”,然后点击 “+ 部署模型” 按钮,选择 “部署基本模型”。
在弹出的对话框中,选择你想要创建的模型后点击 “确认”,在 “部署详细信息” 中点击 “自定义”,设置每分钟令牌数速率限制等选项。最后点击 “部署” 按钮,完成后你就能在当前页面看到新部署的模型。记下模型的 “名称”,以便后续使用。
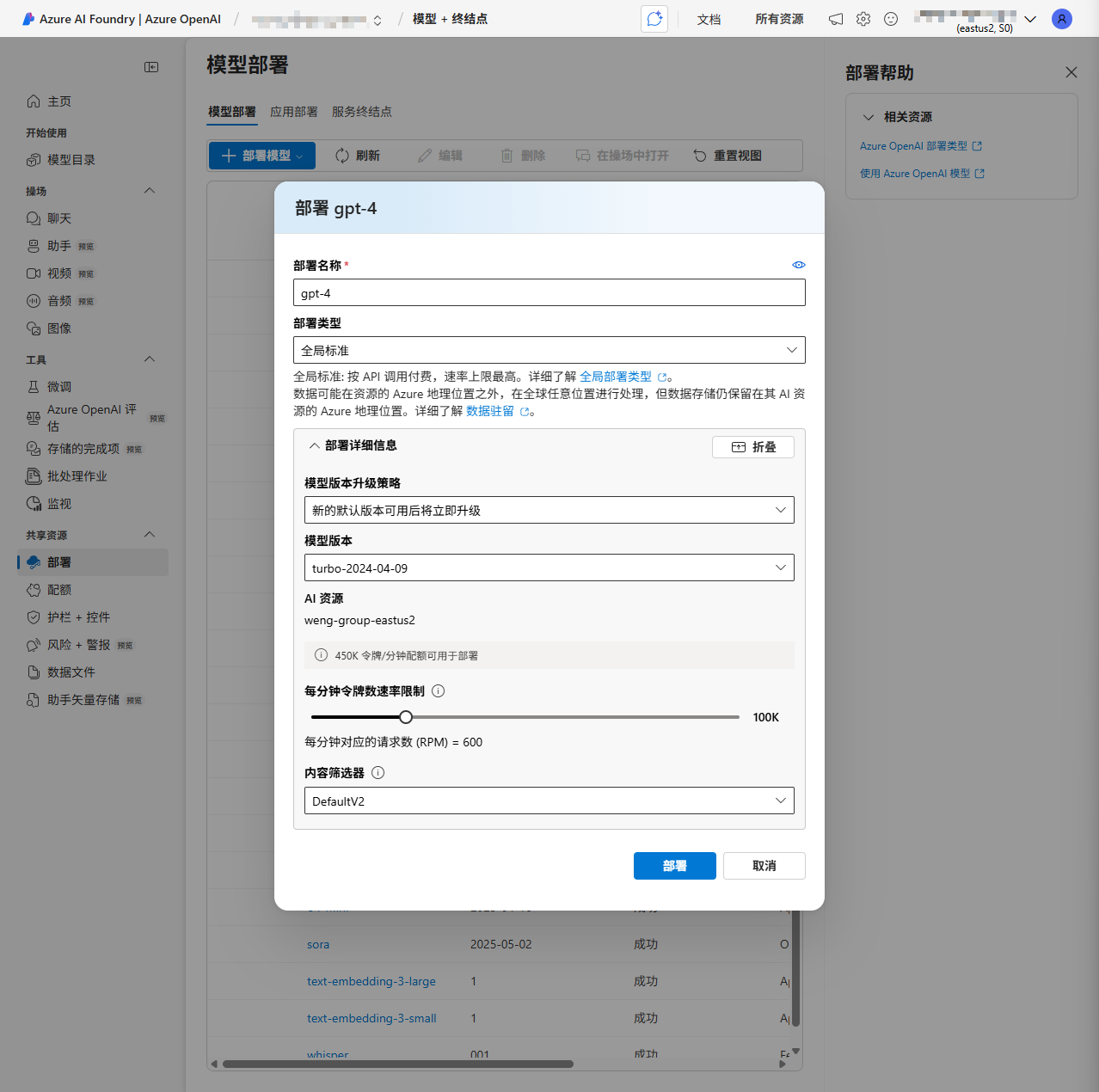
注意,如果 “AI 资源” 处显示的是 “(创建)新名称”,说明当前模型不支持在当前区域部署。你可以点击 “自定义” 后,选择你想部署的资源位置;但请注意:这意味着你需要创建一个新的 AI Foundry 资源,其终结点和密钥将与当前资源不同,所以我们不推荐在本项目中这么做。
搭建私有 AI 对话平台
配置环境
我们希望搭建一个类似 ChatGPT 的 AI 对话平台。在 GitHub 上搜索开源项目后,我找到了一个名为 NextChat 的项目。该项目提供了一个完整的前端和后端解决方案,支持多种部署方式。我在服务器上使用 Docker Compose 部署所有服务,其优点是可以方便地管理多个服务,并且能够轻松地进行扩展和维护。
你需要有一台能连接公网、有公网 IP、预装了 Ubuntu(建议 22.04 及以上版本)的服务器,服务器上需要安装 Docker 和 Docker Compose。如果你没有公网 IP(常见于家庭网络场景),你可以采用内网穿透,或者使用云服务器(如腾讯云等)。
我不建议你使用 apt 的 docker.io 和 docker-compose,而参考 Docker 官方的安装说明(以 Ubuntu 为例)。
在国内环境使用 Docker 时,你可能需要配置国内镜像加速器,以提高下载速度。可以参考阿里云的 Docker 镜像加速器 进行配置。
部署容器
在你的服务器上新建一个文件夹(如 ~/nextchat),并创建 docker-compose.yml 文件(以 nano 编辑器为例):
mkdir ~/nextchat
cd ~/nextchat
nano docker-compose.yml
将以下内容粘贴进编辑器:
services:
chatgpt-web:
image: yidadaa/chatgpt-next-web:latest
volumes:
- ./plugins.json:/app/public/plugins.json
- ./plugins:/app/public/plugins
ports:
- 127.0.0.1:3001:3000
environment:
AZURE_API_KEY: <azure-api-key>
AZURE_URL: <azure-endpoint>
AZURE_API_VERSION: 2024-12-01-preview
CODE: <code>
CUSTOM_MODELS: -all,+gpt-5@Azure,+gpt-5-mini@Azure,+gpt-5-nano@Azure,+gpt-5-chat@Azure,+gpt-4.1@Azure,+gpt-4.1-mini@Azure,+gpt-4.1-nano@Azure,+gpt-4o@Azure,+gpt-4o-mini@Azure,+o4-mini@Azure,+o3@Azure,+o3-mini@Azure,+o1@Azure,+o1-mini@Azure
DEFAULT_MODEL: gpt-5-mini@Azure
HIDE_USER_API_KEY: 1
HIDE_BALANCE_QUERY: 1
restart: always
你需要关注的地方有以下几个:
environment中的变量需要根据你的实际情况进行修改。AZURE_API_KEY、AZURE_URL指定为你先前保存的密钥和终结点,AZURE_API_VERSION指定为你的 API 版本(如果你不知道,可以先使用2024-12-01-preview)。CODE指定为你自定义的登录密码,其他人仅凭借该密码即可访问你的服务。可以用逗号分割多个密码。CUSTOM_MODELS指定为你希望使用的模型,格式为<NextChat显示名称>@Azure=<Azure模型部署名称>。由于你使用的是 Azure OpenAI,模型名称需要指定@Azure。如果两个名称相同,则可以省略=<Azure模型部署名称>。DEFAULT_MODEL指定为你希望使用的默认模型。
ports指定为你希望映射的端口,格式为<宿主机端口>:<容器端口>。容器端口固定为3000,宿主机端口可以自定义,但建议不要使用80和443,以免和其他服务冲突。这里我们将其绑定到127.0.0.1:3001,后面我们会使用 Apache 进行反向代理。volumes的作用是将宿主机的文件挂载到容器中,方便我们后续添加插件。plugins.json是插件列表,plugins是插件文件夹。我们后续将介绍如何添加插件。如果你不需要插件,可以删除这三行(包括volumes)。
通过 Docker Compose 部署(或更新)容器非常简单,只需在 ~/nextchat 目录下运行以下命令:
sudo docker compose up -d
这将会在后台启动容器。你可以通过以下命令查看容器日志:
sudo docker compose logs -f
通过以下命令停止容器:
sudo docker compose down
部署成功后,外网用户仍不能访问你的服务,因为它只监听了本地接口 127.0.0.1:3001。
配置反向代理
为了让外网用户能够访问你的服务,我们建议你购置一个域名(如 mydomain.com),并配置反向代理。这里我们使用 Apache 作为反向代理服务器,Nginx 同理。
在你的服务器上安装 Apache:
sudo apt update
sudo apt install apache2
然后启用代理模块:
sudo a2enmod proxy
sudo a2enmod proxy_http
接下来,创建一个新的虚拟主机配置文件:
sudo nano /etc/apache2/sites-available/nextchat.conf
将以下内容粘贴进编辑器:
<VirtualHost *:80>
ServerName chat.mydomain.com
ProxyPass / http://127.0.0.1:3001/
ProxyPassReverse / http://127.0.0.1:3001/
ErrorLog ${APACHE_LOG_DIR}/nextchat-error.log
CustomLog ${APACHE_LOG_DIR}/nextchat-access.log combined
</VirtualHost>
将 mydomain.com 替换为你的实际域名。我们可以看到,Apache 会将所有请求转发到 http://127.0.0.1:3001/,这正是我们 Docker 容器中应用的地址。如果你启用了 SSL,可以参考以下配置:
<VirtualHost *:80>
ServerName chat.mydomain.com
Redirect permanent / https://chat.mydomain.com/
</VirtualHost>
<VirtualHost *:443>
ServerName chat.mydomain.com
ProxyPass / http://127.0.0.1:3001/
ProxyPassReverse / http://127.0.0.1:3001/
SSLEngine on
SSLCertificateFile /etc/ssl/certs/your-cert.crt
SSLCertificateKeyFile /etc/ssl/private/your-key.key
ErrorLog ${APACHE_LOG_DIR}/nextchat-error.log
CustomLog ${APACHE_LOG_DIR}/nextchat-access.log combined
</VirtualHost>
其中 your-cert.crt 和 your-key.key 是你自己的 SSL 证书和私钥文件。保存并关闭文件后,启用新的虚拟主机配置:
sudo a2ensite nextchat
最后,重启 Apache 使配置生效:
sudo systemctl restart apache2
别忘了在你的域名解析服务商中将 chat.mydomain.com 指向你的服务器 IP 地址。这样,你就可以通过 chat.mydomain.com 访问你的服务了,输入密码后开始使用。
配置插件
NextChat 是支持插件的,详情可参考 NextChat-Awesome-Plugins 仓库,其原理图如下:
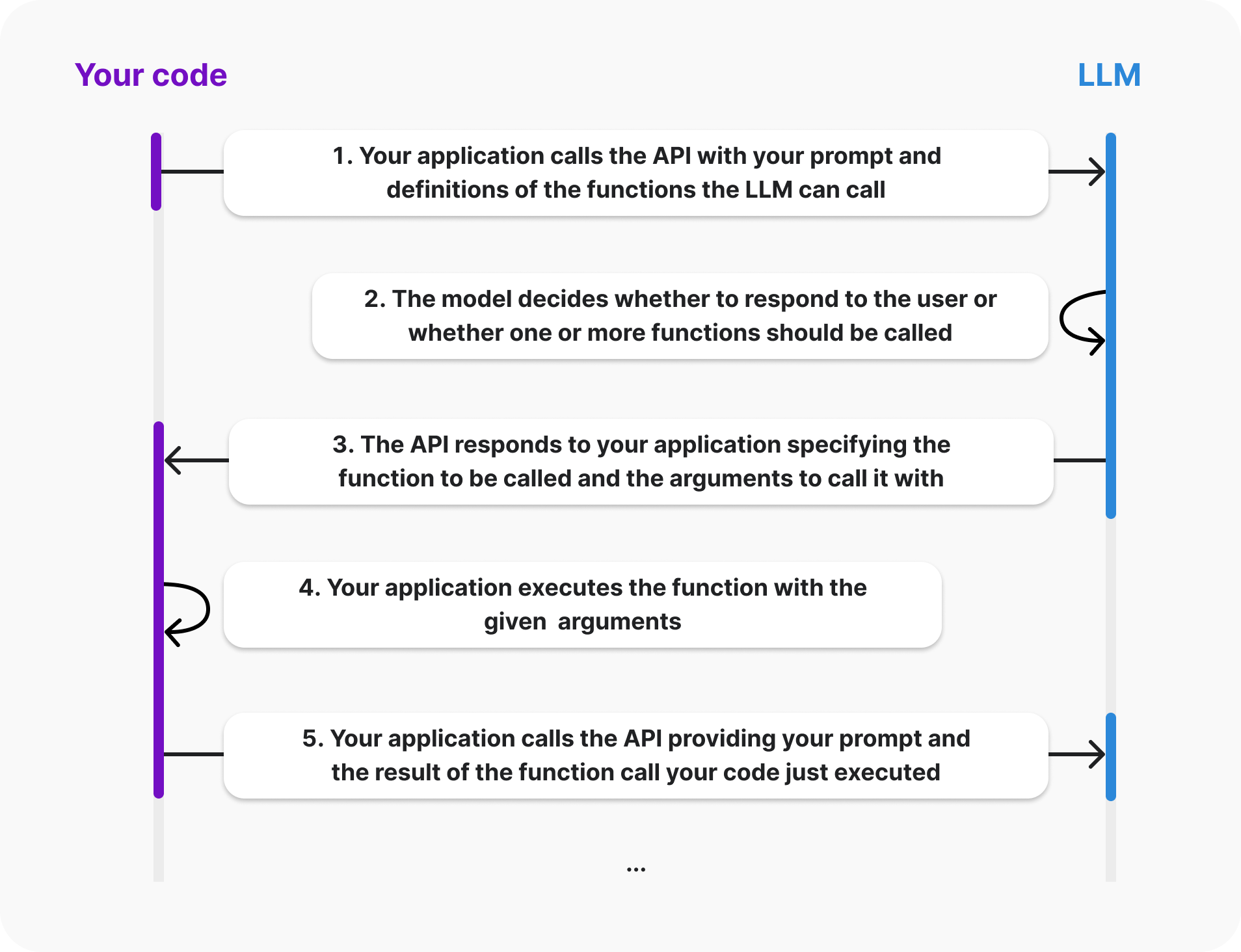
简而言之,插件本质上是个 OpenAPI 请求模板。当你启用插件并指定 LLM 去实现某个特殊任务时,LLM 会调用合适的插件并将请求转发给它,然后将响应加入到 LLM 的上下文中,从而实现更复杂的功能。
NextChat 会预装一些插件,但随着插件供应商的服务更新,有些已不再适用。所以我建议在此处手动预装你需要的插件,这就是我们先前提到的通过挂载宿主机目录的方式来实现的。
我在此处推荐一些实用的插件:
- ArXiv Search:支持在 ArXiv 上搜索论文。
- Code Interpreter:支持在线代码执行。
- Tavily Search & Extract:支持在 Tavily 上搜索和提取信息。
下面介绍如何进行预安装。首先进入到 ~/nextchat 目录,新建 plugins 文件夹和 plugins.json 文件:
cd ~/nextchat
mkdir plugins
touch plugins.json
进入到 plugins 文件夹中,创建插件的 OpenAPI 配置文件:
cd plugins
nano arxivsearch.json
# 粘贴 https://github.com/ChatGPTNextWeb/NextChat-Awesome-Plugins/blob/main/plugins/arxivsearch/openapi.json 的内容,保存并退出
nano codeinterpreterapi.json
nano tavilysearch.json
在创建好插件后,你的 ~/nextchat 目录应该类似下面这样:
.
├── docker-compose.yml
├── plugins
│ ├── arxivsearch.json
│ ├── codeinterpreterapi.json
│ └── tavilysearch.json
└── plugins.json
此外,你需要修改 plugins.json 文件,以包含新创建的插件。确保它看起来像这样:
[
{
"id": "codeinterpreterapi",
"name": "Code Interpreter",
"schema": "/plugins/codeinterpreterapi.json"
},
{
"id": "tavilysearch",
"name": "Tavily Search & Extract",
"schema": "/plugins/tavilysearch.json"
},
{
"id": "arxivsearch",
"name": "Arxiv Search",
"schema": "/plugins/arxivsearch.json"
}
]
最后,重新运行 Docker Compose 更新容器以启用插件:
sudo docker compose up -d
搭建自己的插件服务器
简介
不幸的是,NextChat 原本用于读取 PDF 的 ChatPDF 插件失效了,似乎是插件提供商 AI Document Maker 停止了支持。然而,这个插件却又十分常用且实用,所以我自己动手实现了一个,于是有了 NextChatReadFile(下称本项目、本插件)。
本插件支持读取链接中的 DOCX、PPTX、XLS、XLSX、PDF 等格式的文件,readfile.json 就是本插件的 OpenAPI 模板。你可以将其粘贴至 Swagger Editor 中了解其详细含义。当 LLM 检测到请求中包含读取文件的任务和文件 URL 链接时,其会向 http://nextchat-readfile:8000/read_file 发送 POST 请求,并将文件 URL 作为请求体中 http_url 的值。待服务器返回文件内容时,LLM 会将其纳入上下文中,从而实现对文件内容的访问和处理。
这里的请求地址是一个 Docker 容器名称,相当于内网地址,我们后面会详细介绍。
实现基本功能
由于 NextChat 插件本质上是向插件服务商发送 OpenAPI 模板定义的请求,所以我们只需要在自己的服务器上实现一个的接口即可。这里我选择 Python + FastAPI 来实现这个插件服务器。
实现思路非常简单。对于收到的 http_url,我们需要用 aiohttp 下载文件内容,并将其暂时存在 temp 文件夹中。然后,我们需要解析此文件的内容,并尝试将其转换为文字,这里我们使用微软公司开发的 MarkItDown 库来实现,它支持将应用中常见的 DOCX、PPTX、XLS、XLSX、PDF 等格式转换为 Markdown 格式的文本。最后,我们将转换后的文本作为响应返回给 LLM。
以下是对各个文件和关键代码的说明:
log.py:日志记录模块,负责记录插件服务器的运行日志。model.py:定义数据模型和请求/响应格式。main.py:FastAPI 应用程序的入口点,定义了主要的 API 路由和逻辑。
建议使用 3.10 及以上版本的 Python(例如我的服务器是 3.10.12),使用 pip 安装必要的依赖:
pip install -r requirements.txt
在本地调试时,使用 uvicorn 启动 FastAPI 应用,并将其运行在 8000 端口上:
uvicorn main:app --reload --port 8000
这样你就能在 http://localhost:8000 访问你的插件服务器了。向 http://localhost:8000/read_file 发送请求,即可实现文件读取功能。
如果你需要向外界提供服务,你需要将 uvicorn 的 host 参数设置为 0.0.0.0,使其可以监听所有 IP 地址:
uvicorn main:app --reload --host 0.0.0.0 --port 8000
我将这个项目打包为 Docker 镜像,并上传到了 Docker Hub 上,镜像地址为 na2cucl4/nextchat-readfile:latest。如果你要使用这个镜像,可以参考下面的 Docker Compose 配置文件:
services:
nextchat-readfile:
image: na2cucl4/nextchat-readfile:latest
container_name: nextchat-readfile
expose:
- 8000
restart: always
实现插件通信
NextChat 的 Docker Compose 配置文件的内容如下:
services:
nextchat:
image: yidadaa/chatgpt-next-web:latest
container_name: nextchat
ports:
- 127.0.0.1:3001:3000
environment:
AZURE_API_KEY: <azure-api-key>
AZURE_URL: <azure-endpoint>
AZURE_API_VERSION: 2024-12-01-preview
CODE: <code>
CUSTOM_MODELS: -all,+gpt-5@Azure,+gpt-5-mini@Azure,+gpt-5-nano@Azure,+gpt-5-chat@Azure,+gpt-4.1@Azure,+gpt-4.1-mini@Azure,+gpt-4.1-nano@Azure,+gpt-4o@Azure,+gpt-4o-mini@Azure,+o4-mini@Azure,+o3@Azure,+o3-mini@Azure,+o1@Azure,+o1-mini@Azure
DEFAULT_MODEL: gpt-5-mini@Azure
HIDE_USER_API_KEY: 1
HIDE_BALANCE_QUERY: 1
restart: always
我们将 127.0.0.1:3001 的请求转发到容器内部 3000 端口运行的 NextChat 服务,随后在服务器上配置了 Apache 反向代理,将 https://chat.mydomain.com 的请求转发到 http://localhost:3001。这样,外界就可以通过域名访问 NextChat 服务。
如前文所述,NextChat 的插件通过 HTTP 请求与插件服务器进行通信,具体操作是:将 https://chat.mydomain.com/api/proxy/<path> 的请求转发到 <base>/<path> 处,其中 <base> 由请求头的 X-Base-URL 指定。例如以下两个请求在功能上是等价的:
# 在外界电脑上
curl -X POST https://chat.mydomain.com/api/proxy/read_file -H 'Content-Type: application/json' -H 'X-Base-URL: http://base.url' -d '{"data":"..."}'
# 在部署了 NextChat 的服务器上
curl -X POST http://base.url/read_file -H 'Content-Type: application/json' -d '{"data":"..."}'
为了让 NextChat 能够访问我们刚才搭建的插件服务器,我们需要让它们处于同一个 Docker 网络中。为此,我们可以在 Docker Compose 文件中定义一个自定义网络,例如 nextchat-network,并将两个服务都连接到这个网络上。最终的 Docker Compose 文件参见目录中的 docker-compose.yml。
最后,我们前面提到 readfile.json 中的 url 字段就是 http://nextchat-readfile:8000,这正是我们在 Docker Compose 中为插件服务器指定的服务名称和端口。
附录:使用文档智能提升转换准确度
使用微软 Azure 上的文档智能(Document Intelligence)可以提升文件转换的准确度,但转换速度会显著下降(约为原来的 1/4)。经过实际检验,提升的准确度远不足以弥补性能损失,故在此仅提供实现参考。
import os
from azure.core.credentials import AzureKeyCredential
from markitdown import MarkItDown
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-12-01-preview"
)
md = MarkItDown(
docintel_endpoint=os.getenv("AZURE_DOCINTEL_ENDPOINT"),
docintel_credential=AzureKeyCredential(os.getenv("AZURE_DOCINTEL_API_KEY")),
llm_client=client,
llm_model="gpt-4o"
)
result = md.convert("example.docx")
with open("example.md", "w") as f:
f.write(result.text_content)